2024-2학기에 처음으로 학부연구생 프로그램에 참여하며 Anomaly Detection에 대해 공부할 기회가 있었다. 블로그에 활동 내용을 올려도 될까 여쭤보니 교수님께서 흔쾌히 허락해 주셔서, 한 학기 동안 공부했던 내용을 정리해 업로드해보려 한다.

이상탐지(Anomaly Detection)란 무엇인가?
이상탐지는 데이터에서 정상 샘플과 비정상 샘플을 구분하는 문제를 말한다. 일반적으로 비정상 샘플은 전체 데이터 중 매우 적은 비율을 차지하며, 이를 클래스 불균형(Class Imbalance) 문제라고 한다. 이러한 특성 때문에 이상탐지를 하는 방법론은 기존의 분류문제와는 다른 접근법을 요구한다.
이상탐지 문제 vs 분류 문제
- 분류
분류는 여러 클래스 중 하나를 예측하는 문제이다. 예를 들어, A 설비에서 생산된 제품과 B 설비에서 생산된 제품을 구별하는 작업이 분류에 해당한다.
- 이상탐지
이상탐지는 주어진 데이터가 정상인지 비정상인지 판단하는 문제이다. 예를 들어, 생산된 제품이 불량품인지 아닌지를 확인하는 것이 이상탐지다.
이상탐지는 대부분 비정상 데이터가 드물다는 점에서 분류 문제와 차이가 있다. 비정상 데이터를 학습하기 어려운 경우, 정상 데이터만을 학습하여 비정상 여부를 판단하기도 한다.

이상탐지 모형의 분류

이상탐지 알고리즘을 분류하는 방법은 다양하나, 학습 시에 비정상/정상 데이터의 사용여부에 따라 아래와 같이 구분할 수 있다.
학습 시 비정상 샘플의 사용 여부와 라벨 유무에 따른 이상탐지 분류
1. 지도학습 기반 이상탐지 (Supervised Anomaly Detection)
: 데이터가 라벨링되어 있어야 한다. Class Imbalance 문제가 있으며 기존의 분류 알고리즘을 이용할 수 있다.
- 특징
- 학습 데이터에 정상 샘플과 비정상 샘플의 데이터와 라벨이 모두 존재.
- 높은 정확도가 요구되는 경우에 주로 사용.
- 클래스 불균형 문제 발생: 비정상 샘플의 수가 매우 적어 데이터 수집에 많은 시간과 비용이 소요됨.
- 예: 불량률이 1%라면 100개의 비정상 샘플을 얻기 위해 10,000개의 샘플이 필요.
- 해결 방법: 데이터 증강, 손실 함수 재설계, 배치 샘플링 등의 기법 적용.
- 장점
- 양/불 판정의 정확도가 높다.
- 단점
- 비정상 샘플 수집에 높은 비용과 시간이 요구된다.
- 클래스 불균형 문제를 해결해야 한다.
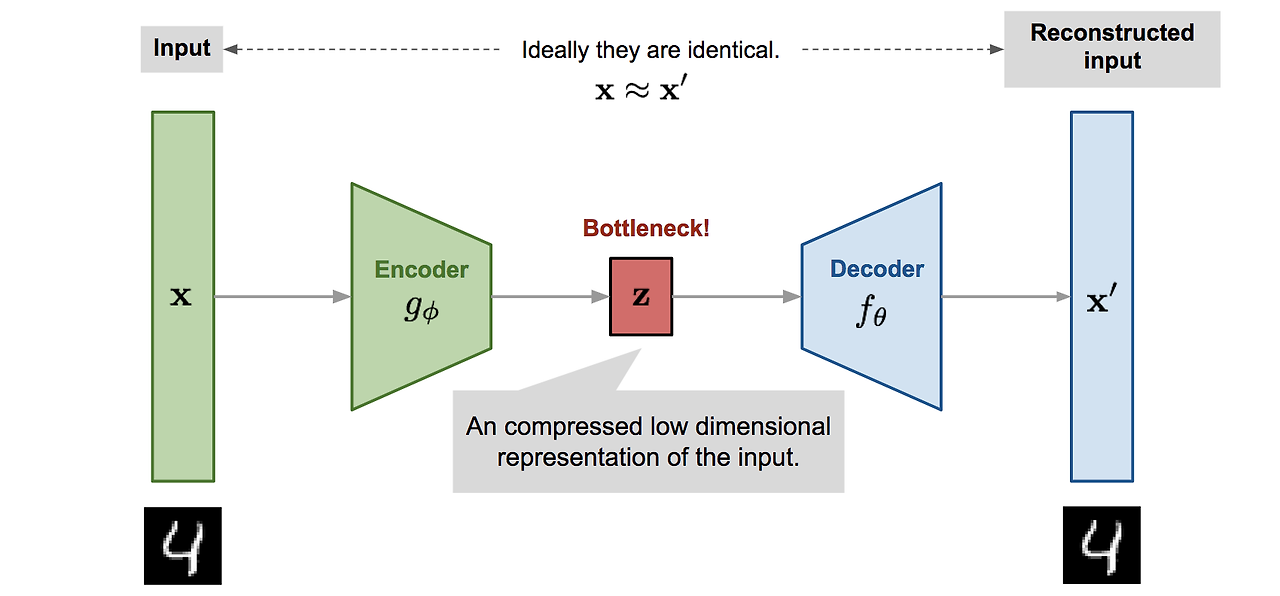
2. 반지도학습(단일 클래스) 기반 이상탐지 (Semi-Supervised Anomaly Detection)
: 정상 데이터만 이용해 모형을 학습시킨다. 다양한 방법으로 Anomlay Score를 계산해 임계값을 넘어가는 데이터를 이상이라고 간주한다.
- 특징
- 정상 데이터만 이용해 모형 학습
- 데이터의 패턴을 학습하여 이상치 스코어(anomaly score)를 계산.
- 이상치 스코어가 사전에 정의된 임계값(threshold)을 초과하면 해당 데이터를 비정상으로 간주.
- 이상치 스코어 계산 방식: 복원 오차(reconstruction error), 거리 기반 스코어, 밀도 기반 스코어 등이 주로 사용.
- 정상 데이터의 범위 결정이 중요:
- 너무 넓은 경계: 정상 샘플 오류(False Alarm)는 적지만, 이상치 탐지 민감도가 낮아짐.
- 너무 좁은 경계: 이상치 탐지 민감도는 높아지지만 False Alarm이 증가.
- 주요 알고리즘
- PCA(주성분 분석)
- 고전적인 차원 축소 기법
- 데이터를 저차원으로 축소했다가 다시 복원했을때 정상데이터가 더 잘 복원될것이라고 가정.
- 재구축 오차가 큰 데이터를 비정상으로 간주.
- Autoencoder(오토인코더)
- PCA와 같은 재구축 오차 기반 이상탐지 알고리즘
- 뉴럴 네트워크 이용해 차원을 축소하고 복원한다는 것이 차이점
- 복원 오차 (reconstruction error)가 큰 데이터를 비정상으로 간주
- PCA(주성분 분석)
- 장점
- 정상 데이터만으로 학습이 가능하므로 라벨링이 필요 없다.
- 복잡한 데이터 구조에도 적용 가능한 다양한 접근법이 존재.
- 이상치 스코어를 활용해 임계값 조정이 용이하다.
- 단점
- 이상치 스코어 계산 및 임계값 설정에 따라 탐지 성능이 크게 달라질 수 있다.
- 데이터의 특성에 따라 하이퍼파라미터 튜닝이 필요하다.
- 지도학습 기반 방법론과 비교해 양/불 판정 정확도가 낮을 수 있다.
3. 비지도학습 기반 이상탐지 (Unsupervised Anomaly Detection)
: 이상탐지 문제에서는 대부분의 데이터가 정상일 것이라고 가정하고, 라벨링 없이 학습하는 방법

- 특징
- 대부분의 데이터를 정상으로 가정하며 라벨 없이 학습.
- 정상 데이터와 비정상 데이터를 사전에 정의하지 않고, 데이터의 패턴과 분포를 분석하여 이상치를 탐지.
- 주요 알고리즘
- One-Class SVM
- 정상 데이터를 둘러싸는 경계를 학습해 초평면 밖의 샘플을 이상치로 간주.
- 커널 함수를 활용해 비선형 데이터에서도 적용 가능하며, 단순한 데이터 구조에 적합.
- Isolation Forest
- 랜덤 트리를 이용해 샘플을 고립시키는 데 필요한 분리 단계를 계산.
- 적은 분리로 고립되는 데이터를 이상치로 간주하며, 대규모 데이터에서도 효과적.
- DBSCAN
- 밀도 기반 클러스터링 알고리즘으로, 클러스터에 속하지 않는 샘플을 이상치로 판단.
- 데이터 밀도와 분포에 민감하지만, 라벨 없이 이상치 탐지가 가능.
- One-Class SVM
- 장점
- 라벨이 필요하지 않아 데이터 준비 과정이 간단하다.
- 대부분의 데이터가 정상이라는 가정 하에서 효과적으로 작동한다.
- 데이터의 구조적 특성을 활용해 이상치를 탐지할 수 있다.
- 단점
- 정상과 비정상의 경계가 모호한 경우 탐지 정확도가 낮아질 수 있다.
- 하이퍼파라미터에 민감하며, 데이터 분포에 따라 성능이 크게 달라질 수 있다.
- 지도학습 기반 방법론과 비교해 양/불 판정 정확도가 낮을 수 있다.
형식을 어느정도 맞추기 위해 장/단점을 구분해 놓았지만, 이는 문제상황에 따라 달라질 수 있다.
앞으로 다양한 이상탐지 알고리즘을 정리해보겠다.
'데이터 분석 > Anomaly Detection 이상탐지' 카테고리의 다른 글
| LOF(Local Outlier Factor) 실습 - PYOD 사용 및 직접 구현 (1) | 2024.12.26 |
|---|---|
| LOF(Local Outlier Factor) - 이론,개념 (0) | 2024.12.24 |